Archive: Feature extraction and fully-connected neural networks
Note: Originally posted April 12th, 2021, this is post in the archived Deep Learning for Computer Vision series (cs231n).
- Browse the full cs231n series.
- See the source code in the features and FullyConnectedNets notebooks.
New comments are found exclusively in info boxes like this one.
I finished the 2-layer neural net in prior post, which was A1:Q4. Today I have A1:Q5 (Extracted features) completed and progress on A2:Q1 (Fully-Connected nets).
Feature Extraction
After putting together a basic 2-layer net, the authors have students do an exercise with extracted features. Feature extraction is the process of distilling some high-dimensional raw input data down to a lower-dimensional representation of the same features/attributes. To minimize loss of information, researchers use their domain expertise to discern higher level information from the dataset and use those instead of raw inputs.
So in cifar-10, raw input for a given sample is just that image’s pixel values. And fortunately for me, the authors brought their own domain expertise and have extracted features for us (a Histogram of oriented gradients and a hsv-rgb histogram, formatted as ndarrays, for each image). All you have to do is reshape them appropriately to plug them into your existing models for training.
Results:
| Model | Feature Type | Target Accuracy | Observed Accuracy |
|---|---|---|---|
| SVM | Raw Pixels | 39%* | 37%* |
| SVM | Extracted | 44% | 40.4% |
| 2-Layer net | Raw Pixels | 48% | 51.7% |
| 2-Layer net | Extracted | 55% | 56.8% |
* Raw Pixel SVM accuracies are in Validation set, not Test.
Fully-Connected Neural Nets
The second assignment starts off by having students perform a thorough refactor on the two-layer neural net produced as part of assignment 1. Importantly, by abstracting the individual layers themselves and their connection points, the student develops an API which can conveniently create fully connected nets of arbitrary depth. Another thing done while refactoring is separating out the training logic in the form of a Solver class from the net (model) itself. This design decision gives the developer a convenient way to change your training optimization method without directly changing the model code.
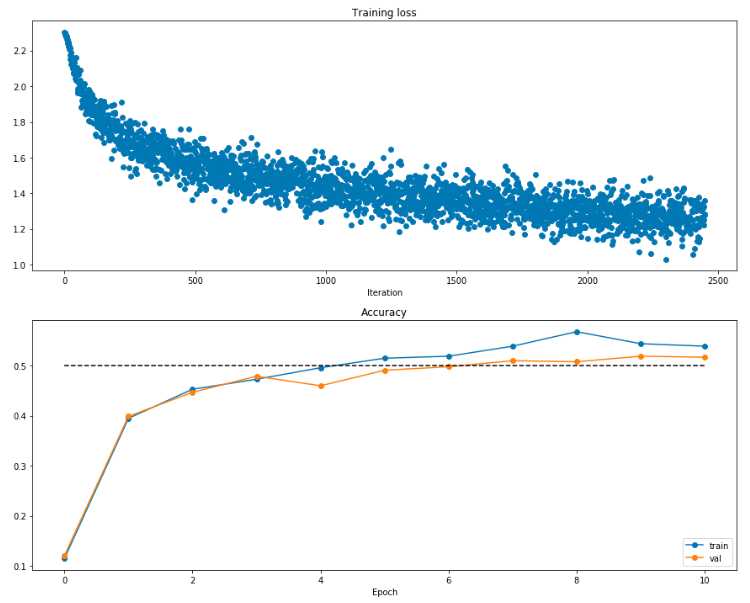
I completed these refactoring steps and verified they’re correct. The assignment has students do this by creating another 2-layer neural net as in the first assignment using the API they’ve (partially) created. Much like the first assignment, I get nets with ~51% accuracy. Here’s a visualization of the training process for a given model:
Todo: A2:Q1 has a few remaining pieces. First students create 3-layer and 5-layer fc-nets in similarly to the 2-layer net. Then the assignment changes direction to focus on new optimization schemes (SGD+momentum, RMSProp, Adam).